
한차례 겪었던 사이트 다운 문제를 다시 겪어서 식겁했다.
댓글 기능을 붙였을 뿐인데 블로그가 죽어버렸다. 그리고 일주일 후, 새 글을 업로드한 직후 또 다운됐다. 두 번 모두 AWS EC2 인스턴스 자체는 켜져 있는데 SSH 연결조차 되지 않는 상태. 재부팅을 수차례 시도하고 도커를 리빌드해서 겨우 복구했다.
같은 현상이 반복되었기에 이번엔 컨테이너별 메모리 사용량까지 살펴보며 디버깅을 시도했다. 그리고 그 과정에서 얻은 인사이트가 꽤 컸다.
문제 상황: 프리티어 t3.micro, Ghost + Docker로 버티는 구조
내 블로그는 AWS EC2 프리티어(t3.micro) 인스턴스 위에서 Docker로 Ghost를 띄운 구조다. 여기에 certbot, nginx proxy, 간단한 backend까지 같이 올라가 있다.
- EC2 인스턴스 (t3.micro)
- RAM: 1GB
- OS: Ubuntu 22.04
- Docker 컨테이너
- Ghost 블로그
- nginx proxy
- certbot
- backend API
트래픽은 거의 없지만 컨테이너가 여러 개라서 부팅만으로도 메모리를 꽤 먹는다. 특히 Ghost 블로그처럼 Docker + nginx + certbot까지 구성한 실제 서비스성 워크로드는 프리티어에서는 안정적으로 돌리기 어려워 보인다.
1차 다운, Cusdis 댓글 기능 삽입 직후
처음 사이트가 다운된 건 댓글 기능을 붙인 이후였다.
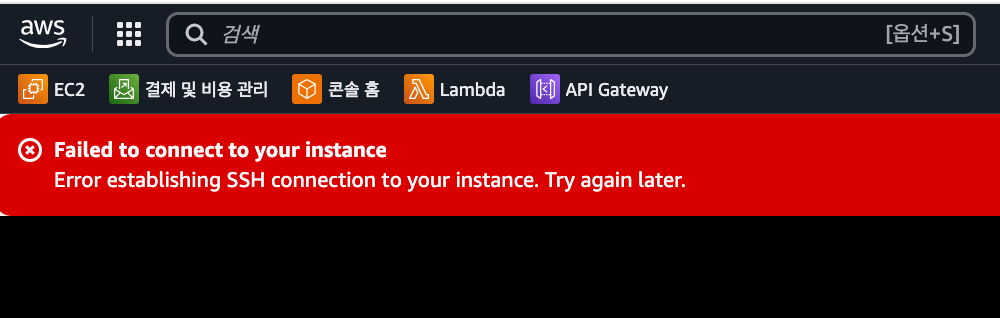
EC2 인스턴스 상태는 정상인데 SSH이 막히고 사이트도 접속 불가. 그러다 조금 기다리니 연결이 되어서 터미널에서 도커를 확인했다. 컨테이너가 모두 죽어있었다. 당시엔 저녁 일정이 있어 급하게 복구하느라 원인 분석을 못 하고 docker-compose up --build -d로 컨테이너를 다시 올렸다.
이때dmesg | grep -i kill로 커널 로그 확인을 시도하면 리눅스가 OOM 상황일 때 어떤 프로세스를 종료했는지 확인 가능. 단, 서버 재부팅 후엔 로그가 사라지기 때문에 즉시 확인하거나 별도로 저장 필요.
근데 나는dmesg | grep -i kill입력 시sudo를 쓰고 임시 제한 해제를 해봐도 접근 권한이 없다고 나왔음. 일부 AWS EC2에서는 root여도 커널 보안 정책 때문에 dmesg 접근이 차단될 수 있다고 함.
2차 다운, 새로운 글 업로드 후 즉시 발생
두 번째는 새 글을 올린 직후, 오전에 사이트가 또 다운됐다. 이쯤 되면 그냥 넘어갈 수 없었다. "이번엔 좀 더 살펴보자" 마음 먹고 다음의 세 가지 명령어로 상태를 점검해보았다.
$ free -h
$ docker ps -a
$ docker stats
당시 free -h로 확인해 본 결과이다.
| 항목 | 전체 (total) | 사용 중 (used) | 남은 공간 (free) | 공유 메모리 (shared) | 버퍼/캐시 (buff/cache) | 사용 가능 (available) |
|---|---|---|---|---|---|---|
| RAM | 914MiB | 584MiB | 70MiB | 3.1MiB | 432MiB | 329MiB |
| Swap | 0B | 0B | 0B | — | — | — |
RAM 914MiB 중 이미 584MiB가 사용 중이고 남은 공간은 고작 70MiB뿐이었다. 버퍼/캐시까지 포함하면 329MiB가 사용 가능하다고 나오지만 실제로는 이미 Swap 공간 없이 RAM만으로 버티는 상태였다.
또한 docker ps -a로 확인해보니 고스트랑 백엔드 컨테이너 5분 전 종료되었고 nginx 계속 재시작중인 상태였다.

nginx 컨테이너에서 Exited (137) 로그가 찍혀 있었다. 이 코드는 리눅스가 메모리 부족(OOM)으로 SIGKILL 시그널을 보내 컨테이너를 강제 종료했다는 뜻이다. 이때 커널은 우선순위가 낮은 프로세스부터 무작위로 죽인다.
컨테이너별 메모리 사용량
컨테이너별 메모리는 docker stats 명령어로 각 컨테이너의 메모리 사용량 / 제한치, CPU 사용률 등을 실시간으로 확인했다.

available: buff/cache를 포함해서 실제로 새 프로세스가 사용할 수 있는 총량
컨테이너에 RAM 제한을 따로 걸지 않았고 모두 호스트 메모리(914MiB)를 공유 중이었다. 이 경우 Ghost가 174MiB, backend가 48MiB를 쓰더라도 시스템 전체 사용량이 커지면 커널이 임의의 컨테이너를 죽일 수 있다. certbot이나 기타 서비스가 병렬로 돌아가면 순간적으로 메모리 여유가 없어지고 바로 OOM 상황으로 빠질 확률은 커질 것이다.
실제 가용량 예상
| 구성 | 예상 사용량 |
|---|---|
| Ghost + nginx + backend | 360~400MiB |
| Ghost + nginx + backend + certbot | 450~500MiB |
아래 항목은 메모리에 포함되지 않는다.
- Docker 데몬 자체 메모리
- Ubuntu OS 커널 및 background 서비스
- buffer/cache (수백 MiB 예상)
리눅스 부팅만 해도 메모리가 쓰이고 Docker 데몬도 계속 메모리를 점유해 400~600MiB 정도를 사용하는 것으로 추측. certbot처럼 순간적으로 peak를 치는 작업이 들어오면 여유 공간은 더 줄어든다. 버퍼나 캐시까지 포함하면 실제 usable 메모리는 600MiB도 안 될 수 있다. 결국 t3.micro(1GB)는 컨테이너 몇 개만 띄워도 이미 임계점에 다다른다.
스왑 메모리 추가로 OOM 방지 시도
리눅스는 스왑 메모리가 설정되어 있으면 RAM이 꽉 차도 시스템을 바로 죽이지 않고 버틴다. 그래서 바로 스왑을 추가했다.
sudo fallocate -l 1G /swapfile
sudo chmod 600 /swapfile
sudo mkswap /swapfile
sudo swapon /swapfile
sudo bash -c 'echo "/swapfile none swap sw 0 0" >> /etc/fstab'
스왑은 디스크를 보조 메모리처럼 사용하는 공간이지만 속도는 훨씬 느리다. 비유하자면 아래와 같다고.(책 찾으러 어디까지 가는데..)
| 자원 | 속도 | 비유 |
|---|---|---|
| RAM | 💨 빠름 (나노초) | 작업실 바로 옆 책상 |
| Swap (디스크) | 🐌 매우 느림 (마이크로~밀리초) | 옥상 창고 올라가서 책 찾는 느낌 |
스왑 설정 이후 메모리 사용량


회고 시점에 재확인해보니 스왑이 이미 쓰이고 있었다. 현재 시스템 메모리 중 완전히 비어 있는 공간은 75MiB에 불과하다. 게다가 Swap 설정해둔 부분 중 260MiB가 사용 중인 상태다. 겉으로 보기에 available은 286MiB로 여유 있어 보이지만 이미 Swap이 사용중인 상황으로 보아 사실상 메모리 부족. 이 상태가 계속되면 다시 프로세스가 강제 종료될 가능성도 있다.
SSG 구조로 바꿔야 하나?
램이 1GB라면 SSR보단 SSG가 나을 수도 있겠다는 조언을 들었다. 고스트 같은 SSR방식은 글 하나를 띄울 때도 서버에서 렌더링하기 때문에 작은 인스턴스에서는 부담이다. SSG는 미리 HTML을 만들어두기 때문에 서버 자원 소모가 거의 없다.
Ghost는 SSR 구조라 정적 구성 시 빠르고 가벼워지겠지만 글을 새로 쓸 때마다 자동으로 빌드-배포되도록 시스템화를 해야한다는 점이 고민이다. 반면 자동화 해두면 편하기도 하고 RAM 압박이 줄어든다는 점에서 메리트가 있다.
- SSR(Server-Side Rendering): 매번 서버에서 HTML 렌더링 → 동적, 무겁다
- SSG(Static Site Generation): 미리 HTML 생성 → 가볍, 새 글 반영에 빌드 필요
우선은 좀 더 지켜보고 방향을 고민해보려 한다. 이외에 다른 방법이 있을지도 찾아봤다.
t3.small 인스턴스 업그레이드 고려
| 항목 | t3.micro | t3.small |
|---|---|---|
| RAM | 1GB | 2GB |
| 월비용 | 무료 (프리티어) | 약 20,000원 |
| 안정성 | 자주 죽음 | 실서비스 가능 |
위에서 알아본 바와 같이 Ghost + Docker + certbot 구성에선 1GB로는 버티기 어려워 보인다. 딱 1GB 차이지만 서비스가 죽느냐 마느냐가 달라진다. t3.small 정도는 되어야 안정적일 것 같긴 하다.
마무리하며
이번엔 단순히 컨테이너를 kill했다가 다시 띄우는 것으로 끝내지 않았고, 덕분에 큰 수확이 있었다.
처음엔 그냥 "OOM으로 메모리가 부족했구나" 하고 넘길 뻔했는데 컨테이너별 종료 로그, 메모리 사용량, 시스템 가용량, 스왑 상태까지 하나씩 짚어보며 원인을 구체적으로 파악할 수 있었다. (도움 주신 개발자님께 감사드립니다!)
중요한 건 추측이 아닌 실측, 그리고 단계별 로그를 쪼개서 보는 습관이라는 걸 새삼 느꼈다.
사이트가 다운되면 아무리 멋진 기능을 붙여놔도, 좋은 콘텐츠가 있어도 소용없다. 이번 경험을 통해 구조와 리소스를 고민하지 않은 채 기능만 늘리면 문제가 생긴다는 사실을 절실히 깨달았다. 단순한 복구를 넘어 서비스 아키텍처와 운영 구조에 대한 배움으로 이어진 값진 계기였다.


